Application savings are locked behind infrastructure credibility
The largest cloud cost savings live in application code owned by other teams. Reaching them requires trust built through infrastructure wins.
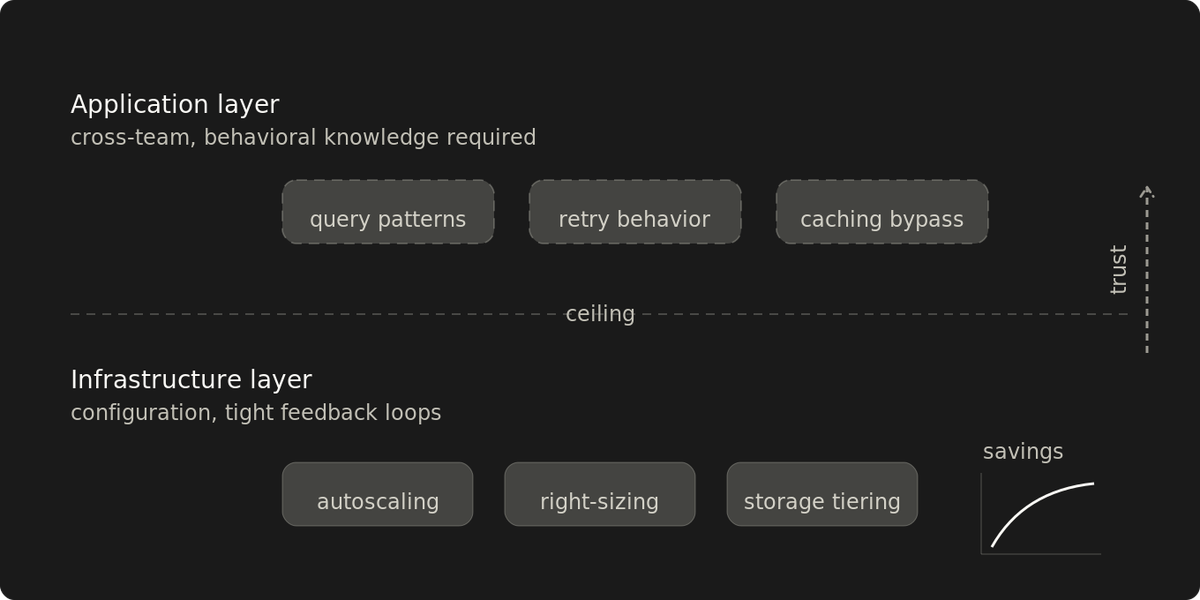
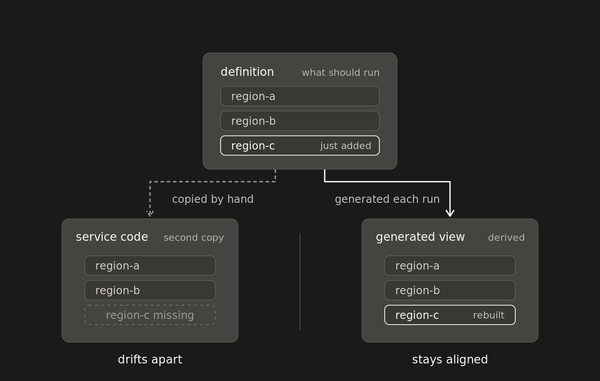
Once the configuration layer is exhausted, the largest remaining cost savings live in application code owned by other teams.
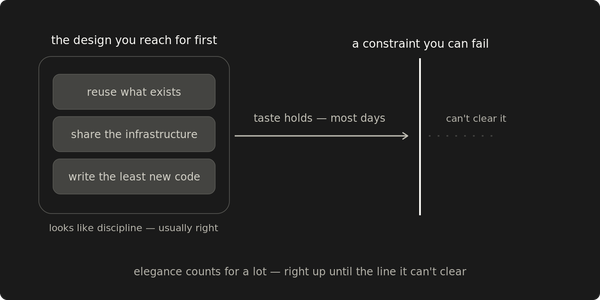
Infrastructure optimization handles the configuration layer: autoscaling, resource allocation, instance scheduling, and orphan cleanup. Results land within a billing cycle. But the configuration layer has diminishing returns, and the remaining cost drivers are application-owned: services, queries, caching patterns, code that belongs to other teams.
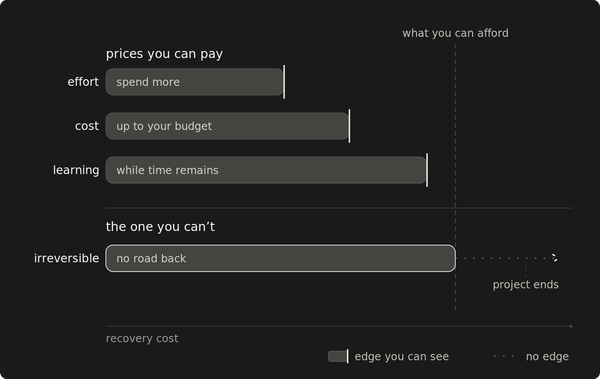
The cheapest savings land first. The biggest ones come last, because they depend on the knowledge and credibility that infrastructure work builds.
The configuration layer has a ceiling
and
The signal is in the type of remaining opportunities. When every change yields single-digit improvements, and the remaining cost drivers are all application behavior, the configuration surface is exhausted. Traffic growth can mask this. A flat bill doesn't mean the limit is reached if new workloads absorb the gains. The diagnostic is the opportunity set, not the bill trajectory.
Below that ceiling, infrastructure work generates more than cost reduction. Fleet cost reporting surfaces that services consume disproportionate resources and where traffic concentrates. Tuning autoscaling against real traffic teaches you why a given service is sized as it is and which scaling patterns signal application-level waste. Cost attribution tools show what's expensive and when.
What they don't show is the cost rationale: why an allocation is sized the way it is, and whether it's right for a workload that only peaks in certain windows. Tracing can surface which service drives a downstream load. It still can't tell you whether that load is worth the cost. That's what explains a database tier staying provisioned for a peak, only one service's retry logic creates, or a cost spike that lines up with a batch window.
Application-level proposals depend on behavioral knowledge
A resource that appears oversized on a dashboard might be correctly provisioned for a workload pattern that only occurs during specific windows. Retry behavior in a downstream service can inflate an allocation that looks wasteful from the outside.
Infrastructure tuning generates this knowledge as a side effect. Each anomaly you investigate ties a cost spike to a specific interaction pattern. The work builds a behavioral model that no dashboard provides because it must understand why each resource is sized as it is. You only learn that when you try to change it.
Demonstrated results change how teams receive proposals
The team that owns the application code needs to verify that the analysis is accurate and that the proposed trade-off holds under production conditions.
Mandated changes without that track record produce compliance. The owning team implements the minimum change necessary to satisfy the requirement. When demonstrated platform knowledge backs the mandate, the owning team engages more deeply: it tests the tradeoff against its own understanding, surfaces constraints the analysis missed, and proposes alternatives that achieve the same savings with less risk. Knowledge earns the technical hearing. The track record in the cost reports warrants action.
A cost reduction that shows up in the monthly report changes the conversation. The platform team's track record is already in the budget data when it asks teams to change their code.
Proposals without empirical backing face reasonable resistance
Analysis built solely on cost attribution references behavior the analyst hasn't observed firsthand. When the owning team asks questions that attribution data can't answer — why the allocation is that size, what happens during the batch window, whether the proposed change affects a downstream dependency — the proposal stalls.
When the analysis misses something, the correction comes from the owning team. Building from correction is slower than building from demonstrated depth.
Meanwhile, infrastructure savings that require less cross-team coordination sit untouched. The initiative spent its early credibility budget on a cold proposal. Pressure for visible progress goes unanswered.
solely on cost attribution
Infrastructure work requires less coordination, and it's usually the most practical way to produce both behavioral knowledge and visible results. Application-level work depends on having both.
Infrastructure changes land within a billing cycle. That matters when leadership wants progress on the cost line this quarter. The biggest savings take longer because they depend on knowledge and credibility that most reliably accumulate through the smaller ones.
The ceiling is visible when each change yields marginal improvements, and the top cost drivers are all application-owned. Application-level work is ready when the platform team describes a service's cost behavior, the owning team recognizes it as accurate, and starts asking what to change. Architectural work starts when teams bring cost questions unprompted.
Early infrastructure wins are how you earn your way above the ceiling.