Redundancy ends where the dependency tree converges
Two backups, two providers, two regions. None of it is redundancy if components share a dependency anyone forgot to map. The failure proves which.
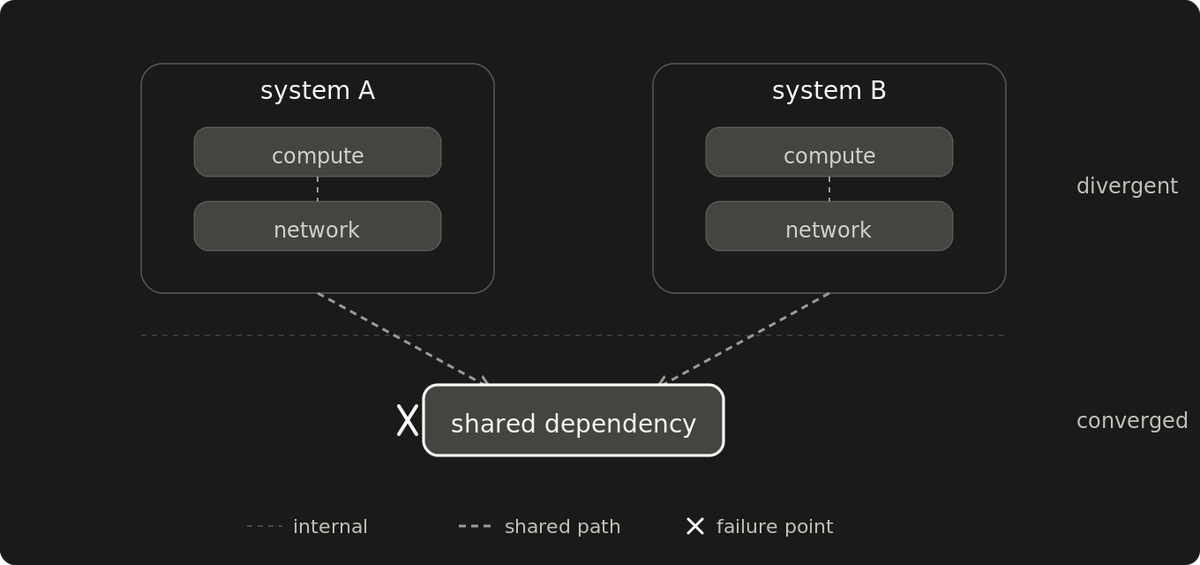
Primary and backup look separate on paper. They behave like two systems only when they fail independently. The component count says nothing about which case applies. The failure proves it.
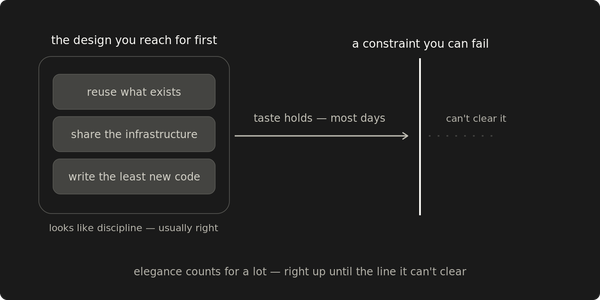
For every component called redundant, the diagnostic is one sentence: what is the smallest set of failures that takes down both? If the answer is one, the redundancy is decorative at that layer. The "one" might be a cable, a building, a provider, a power feed, an operator with credentials, a billing relationship, a global-services control plane, a shared agent on every host, an upstream artifact in the supply chain. Whether to accept it as a deliberate trade-off depends on a second question: can the state migrate off the converged layer during its own failure?
The dependency tree converges before the failure does
Every component sits on a stack of dependencies it doesn't own. Power feed. Cooling loop. Network path. Upstream provider. DNS. Physical building. Identity provider. The operator with the credentials. The agent installed across the fleet. Add a redundant peer at any layer and the system inherits the same dependencies one layer up.
Two servers in one rack share a power feed. Two racks in one building share a fiber path. Two regions on one cloud have far more in common than the diagram shows: an account, a billing relationship, a global identity surface, and a single human whose credentials work in both. Two providers fronted by the same DNS share the DNS. Two clouds running the same agent share a supply chain. The list extends upward. Every redundant pair has a layer above it where it stops being two things.
A shared dependency synchronizes failures. A single failure at the convergence point takes both components in the same incident. For failure-tolerance purposes they are one component, however many divergent instances depend on it. On the divergent side of the convergence point, the components fail independently. On the shared side, they are one system wearing two names.
What redundant looks like before the failure proves it isn't
For years, the disaster recovery looked real. The diagram had multiple servers. Cold spares racked and ready. Daily backups completing every night. Multiple upstream carriers in the contract. Geographic redundancy in the marketing copy. The bill matched the diagram. The runbook referenced the failover path. The drills had covered server failure, never building isolation.
A fiber cut isolated the building.
Inside, power, cooling, and generators kept running. Outside, nothing reached the internet for 24 hours. The operators couldn't reach the systems either. The redundant carriers existed in the contract, but the second feed had been ordered, not provisioned. The cold spares, the daily backups, and the disaster recovery plan all sat behind the same fiber that had been cut.
Recovery waited on the repair. The one off-site layer already in place was a managed DNS service hosted by a third party, bought a year earlier after a separate DNS outage taught a narrow lesson: nameservers can't live on the servers they're supposed to redirect away from. That single piece of off-site separation was the one layer whose topology was already right.
The cost outlasts the outage
A single component outage is a routine event. An outage of the entire failure-recovery stack is a different category. Direct cost: 24 hours offline, multi-day client recovery, credits paid out in compensation, and a short-term inability to raise prices. Indirect cost: years operating under a belief about the redundancy that no failure had pressure-tested. The diagrams agreed with the bill. The runbook agreed with the diagrams. Topology was the only thing wrong, and topology stays invisible until a failure surfaces it.
Independence lives in the failure paths, not the count
Independence holds when two providers don't share an upstream layer: physical medium, geographic region, billing relationship, global-services control plane, identity provider, supply chain, operator. Two backups are two backups when nothing they share takes both at once: corruption mode, storage path, access credentials, the scheduler or agent that drives them. A pair of failover paths is genuinely a pair only when the trigger for one isn't also the trigger for the other.
The rebuilt architecture put primary infrastructure on one cloud, a warm standby and backups on a different cloud, and DNS through a managed provider that ran on neither.
The third-party DNS introduced a new converged dependency: its failure would interrupt routing. So the zone was mirrored to a second authoritative provider, pre-loaded and ready to answer, not just a copied file that resolves nothing, with the failover records kept at a low TTL as steady state. When a cloud fails and DNS still works, flipping that record moves traffic to the warm standby in minutes. When the DNS provider itself fails, you repoint the nameservers at the registrar to the standby provider. Escape is then bounded by nameserver TTL and resolver-cache expiry, not the failed provider's recovery, as long as the registrar is a separate vendor you can still reach.
Storage with no copy outside a failed cloud provider can't escape until the provider recovers. That's the trap that made the fiber cut unrecoverable. The architecture moved the residual shared layer to the one whose state could be migrated off during its own failure.
For regional or account-level events on the active provider, the cutover became a 30-minute operation. End-to-end recovery extended beyond that when replication lag, cached DNS, or stateful service rehydration dominated.
At a smaller scale, the same rule produces a different topology. My home office runs two connectivity tiers: fiber and satellite, both on backup power. Their connectivity paths are independent, fiber against satellite, overlapping only on regional weather. They still share backup power, the building, and the one operator, residual single points I accept at this scale. Failover thresholds are tuned to how long I can drop out of a Zoom call without losing context, not to provider SLA percentiles. Fifteen months in, a 30-day primary outage passed without disrupting my daily workflow.
Name the layers, then decide which ones stay
Run the diagnostic against every "alternative" path in production. The pairs where the answer surprises the team are the layers that haven't failed yet. The list grows with every novel failure.
Not every converged dependency justifies the cost of separating it. Some residual single points are deliberate trade-offs because their state stays portable when they fail. The discipline is to name every shared layer, then decide which ones can stay.
The cheapest moment to discover a converged dependency is during design, when the cost is only architectural thought. The most expensive moment is the one where a single failure resolves the question for the team, in production, with the recovery resources sitting behind the same dependency that just failed.