Budget constraints are architecture inputs
A spending ceiling changes which tools get selected, where capabilities live, and what never enters the stack.
A budget is an architectural boundary condition. It decides which capabilities exist, where they live, and which risks remain unfunded. Under real uptime pressure, that boundary produces engineering discipline. Without uptime pressure, the same budget just produces cheaper systems.
On a tight budget, every decision runs through a filter: does this solve a problem that costs money or sleep right now? What survives is right-sized to actual operational pain, not to speculative complexity that accumulates when the filter is optional.
Spending ceilings change, which tools get selected
When budget pressure is low, teams approve tooling for potential future needs, and the stack expands faster than actual operational pain warrants. The CI platform is approved for workflows that might be needed eventually. The monitoring stack expands for comprehensiveness. The orchestration layer arrives because the architecture might grow into it. Every tool made sense when it was approved. Six months later, you're maintaining nine components for three actual problems, and each one carries a maintenance cost the budget didn't account for.
Under a spending ceiling, instrumentation has to justify itself against actual failure cost. A tool enters the stack when a specific problem crosses the threshold where the fix is cheaper than the pain. Almost nothing enters speculation.
Builds started producing different artifacts on different developers' laptops. Same source, different output depending on each laptop's library versions. Maven fixed that. Standardized builds, reproducible output, zero additional infrastructure cost.
Manual deployments at midnight were costing sleep and producing errors on revenue-critical systems. Jenkins removed that labor and the operator error that came with it.
The source control platform changed its pricing. Once admin and maintenance costs were counted, self-hosting became uneconomical. GitLab's free license included unlimited users, giving customers direct visibility into the build and deployment flow without incurring a seat cost.
Customer expectations are the harder constraint
Budget was not the quality floor. Customer expectations were.
Operational systems (anything where downtime stops someone's work) create an implicit SLA regardless of what's written in a contract. Customers don't track your infrastructure costs. They track whether the system works when they need it. The gap between what customers expect and what the budget allows adds a second decision rule: does this solve the customer's actual problem, or a problem the customer doesn't have?
Monitoring targets page load times and availability, the metrics that generate phone calls. Past a certain point, observability starts paying to debug the complexity that the architecture should have rejected earlier.
Across fifteen production systems, the gap held for over a decade. Infrastructure monitoring used free uptime and response-time tools. Application monitoring was a log parser that sent emails. Logging levels determined alarm severity, and an error-level log triggered a page. Often, the monitoring caught the failure before a customer contacted support, and the fix was already underway. That constraint shaped the code itself. If the monitoring were simple, the code would have to be ruthless about error handling. Every logged error had to mean something actionable.
Capabilities land in the cheapest layer that holds them
Not having a dedicated operations role didn't eliminate ops. It concentrated architectural responsibility. The same people writing application code built every operational capability, maintained it, and got paged when it broke. When the builders carry the operational consequences, architecture gets simpler and sharper. These mechanisms fit the workload: session-based Java web applications on single servers, deployed during off-hours. A different workload shape would have produced different mechanisms. The constraint logic is the same.
Zero-downtime deployment came from the cheapest mechanism available: Tomcat's parallel deployment on a single server with versioned WAR files. Requests carrying a session from the old version keep routing to the old one, while new sessions hit the new one. The mechanism that made this safe was a database compatibility contract built for the purpose: additive schema changes only, no drops or renames until the old version is fully retired. The contract did the heavy lifting. The rare change that required a drop or rename took place during a planned maintenance window. Tomcat routed each request to whichever deployed version already held a live session for its JSESSIONID. Sessionless requests were routed to the latest version. Zero additional infrastructure cost.
Automated recovery came from the same pressure. A watchdog script started Tomcat if it was stopped, restarted it if the application stopped responding, and restarted it if memory usage exceeded a threshold. Every restart triggered a page. A restart also dropped the in-flight sessions on that single server, a brief hit, the no-redundancy model accepted in exchange for automatic recovery. The system came back on its own, and we investigated the root cause before the next failure. The chain held for that operating model, on single servers with no load balancers or redundant instances.
The filter is reactive
Pain-driven filters evaluate what has already hurt. They can't address risks that haven't materialized. Every system running under budget constraints carries gaps that the filter hasn't been forced to evaluate. The failure that would expose them hasn't arrived yet.
The data center had redundant power, multiple upstream carriers, and 24/7 operations staff. Road construction severed a fiber line on a nearby highway, and the facility's redundant fiber feeds weren't live yet. Six years of continuous operation, isolated in an afternoon. Daily backups, cold spares, tested recovery procedures — all in the same building as production. Inaccessible.
The constraint logic had evaluated geographic redundancy and rejected it. A second dedicated server with a different provider would have doubled the infrastructure bill for a cold spare that might never be activated. The datacenter's own redundancy specs made that tradeoff defensible. Customers expected the systems to work, but geographic redundancy had never failed, so the expectation never pushed the architecture past what the budget could justify.
The fiber cut moved geographic redundancy from a risk that hadn't materialized into one that had. The immediate response went through the same filter: offsite backups to a second provider's object storage. Daily backup archives, recoverable to any provider. The cheapest fix that addressed the newly materialized risk.
The cloud migration came later, when it made financial and operational sense on its own terms. DigitalOcean's $5/month base price made the economics work. Each customer system was moved to its own right-sized cloud instance at $12-$24/month, replacing a monolithic bare-metal bill. The migration also resolved the geographic redundancy gap the fiber cut had put on the radar: each system ran in its own region, and a cross-provider offsite backup kept a recoverable copy outside that region.
RTO dropped from 24 hours to 30 minutes per system. RPO stayed at 24 hours for daily offsite backups because continuous replication would have consumed the destination instance's resources and eaten into the margin. Cold multi-cloud DR at $10/month total. Thirty-minute recovery without turning low-margin hosting into a loss leader. Cold described the DR posture, not the storage tier. The backups sat in standard object storage, so restores stayed fast with no retrieval delay or fees. The small premium over an archival tier was the price of a predictable thirty minutes. We tested the restore monthly.
Even after cloud pricing made geographic redundancy affordable, the filter still applied: cold redundancy, because hot replication would eat the margin.
Constraints compound into margin discipline
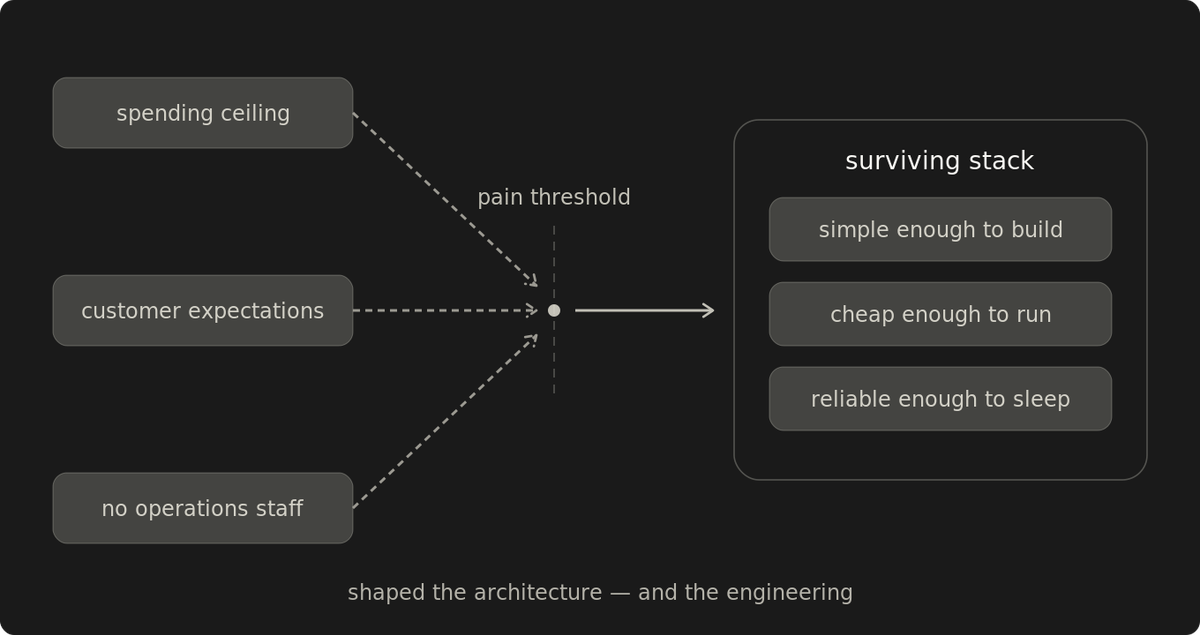
Budget, headcount, and customer expectations each shaped the architecture independently. Together, they forced an engineering discipline that none of them would have produced alone.
The spending ceiling kept the stack small. No operations role meant the people who built the systems carried the consequences of every shortcut. Customer expectations set the quality floor. Under all three, every capability had to be simple enough to build, cheap enough to run, and reliable enough that the person who shipped it could sleep.
Left unchecked, budgets drift toward watching edge cases that rarely cost anything and away from the controls that keep the system up and paying its way. The filter is what stops that drift.
Isolate the real failure mode. Place the capability at the cheapest layer that holds it. Speculative complexity doesn't pass the filter.
Under hard constraints, every architectural decision is a margin decision under uptime pressure.