Treat your own future memory as unreliable infrastructure
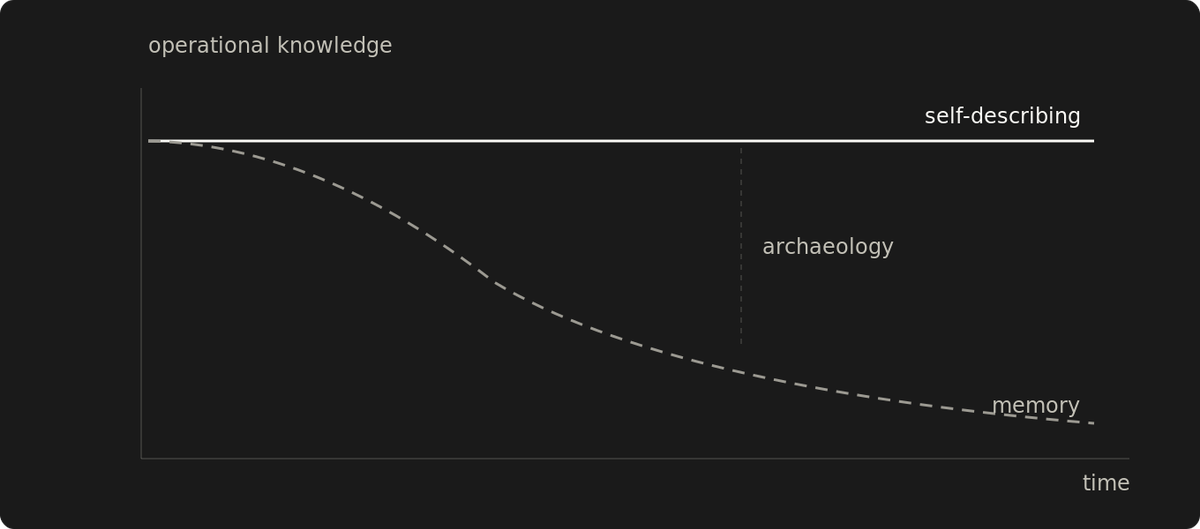
Memory degrades, doesn't transfer, doesn't scale. Self-describing systems survive when the builder forgets, leaves, or gets outnumbered.
Memory fails silently.
A system runs for months. The person who configured it moves to another team, takes a new job, or stops thinking about it long enough for the details to fade. Why this timeout, why that directory structure, why this dependency pinned to that version? Those decisions live nowhere except inside someone's head. When something breaks, recovery starts with archaeology.
Memory as a system of record fails in predictable ways. You forget how your own systems work on a timeline you can't predict. Knowledge leaves when the builder leaves. Beyond a certain number of services, configurations, and dependency interactions, no single person can hold the full picture anyway. Classic single-point-of-failure territory. This one is fixable by design.
Documentation decays on the same timeline
The standard response is documentation.
Writing things down removes the single-person dependency. But documentation that lives separately from the system it describes carries its own failure modes.
Separate documentation requires parallel maintenance. The system changes; the documentation has to change in lockstep. That coupling sounds manageable. Even automating the sync means maintaining two artifacts that could be one. That lockstep breaks under real operational pressure. Changes ship under deadlines. The doc update gets deferred. After enough deferrals, the runbook describes a step that no longer exists. The documentation hasn't failed visibly. It's still there, still readable, still confident in its claims. Silently wrong.
A wiki page documenting a critical recovery procedure has zero value if the person who needs it doesn't know it exists, can't find it under pressure, or finds three versions and can't tell which one is current.
The medium changed. The failure mode didn't.
Self-describing systems break the decay curve
Design every system assuming the person who built it will forget how it works. Including you. That's the principle: treat your own future memory as unreliable infrastructure, and design around the failure before it happens.
The constraint that follows is to make the system answer questions about itself. Convention over configuration deletes decisions before anyone has to remember them. But a convention you can't read off the artifact still has to be remembered. Convention works when it's discoverable from the system itself, not when it's tribal shorthand that requires insider knowledge.
For the operational state, the thing that runs should also be the thing that explains itself. Change the mechanism, and you change its description, because they're one object. Architecture rationale, compliance context, and incident history still need a home. The goal is to reduce the extent to which the operational surface depends on memory.
If you need a wiki page to operate the system, the system isn't designed for amnesia. A --help flag announces its own entry points. A buried wiki URL assumes you already know where to look.
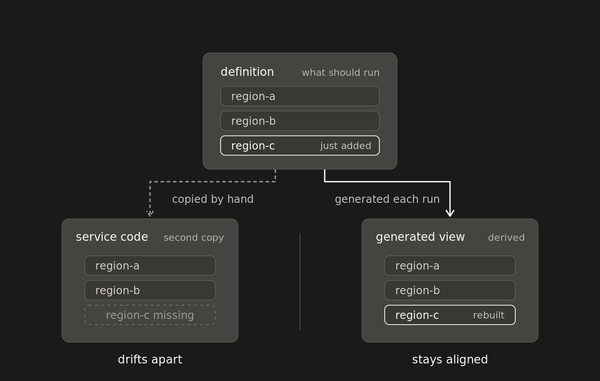
A repository that deploys is also a repository that describes. When the same artifact stores configuration and triggers deployment, reading the repo tells you what the system should be running without asking the person who deployed it. git log captures what someone committed and when. Intended changes to the declared state, not operational history.
Recovery from total loss starts with the repo. Secrets and bootstrap dependencies live outside it, but the repo declares what's needed. Convention makes them discoverable without asking someone.
Executable processes are their own narration. Scheduled automation that pulls configuration and deploys it is both the mechanism and the evidence that it runs. A runbook covering the same ground is a shadow copy. Useful as a fallback. Dangerous when the two diverge.
A declared, versioned monitoring surface replaces the undocumented setup of what gets watched. When dashboard configuration lives alongside service definitions in the same repo, the monitoring setup is inspectable and shareable — not locked in one operator's head.
Drift between the repo and the running system has a mechanism documentation lacks. A reconciler compares the declared state against the actual and corrects the gap. A scheduled pull-and-deploy is weaker: it overwrites drift on its next run without ever comparing. Both still only see what's declared, the same blind spot as a wrong check. Documentation drift has no equivalent.
The decision you eliminate can't be forgotten
The second technique is to remove future decisions entirely.
Every system has renewal points: registrations that expire, certificates that rotate, and configurations that need periodic review. Each one is a future moment when someone needs to remember that something exists, recognize that it needs attention, and know what to do about it.
Automated renewal with safety buffers that outlast human attention spans means the system handles its own maintenance cycle. Multi-year registrations reduce frequency; automated monitoring catches what falls between cycles.
Every scheduled manual action is a bet that future-someone will remember to do it and how. Time-gated automation replaces both. Why it matters is rationale, and that still needs a decision record. A scheduled run also doubles as a staleness gate, but only if it reports its result. A missed or failed run then surfaces at the next interval. Without that wiring, a broken schedule fails as silently as the wiki it replaced. Success means the mechanism ran. Whether it ran against the right target needs its own check.
and
Wrong checks are worse than no checks
A green dashboard builds confidence that backups are healthy. The dashboard checks what someone configured it to check. Wrong checks produce false confidence, and false confidence is harder to debug than honest ignorance because it delays discovery. The failure compounds silently for as long as the wrong check stays green. By the time someone needs the backup, the gap has been growing undetected. Dashboards decay the same way wikis do.
Some operational knowledge resists automation entirely: which failure scenarios the team has survived before, what a quarterly traffic spike does to cache coherence, and why a workaround exists that nobody thought to label as one. That's where traditional documentation earns its keep — for knowledge that mechanisms can't carry. The most durable form captures decisions at the moment they're made. Decision records describe a fixed point in time and don't require parallel maintenance.
Retrospective summaries lose the constraints and tradeoffs that shaped the decision. Self-describing infrastructure reduces the surface area on which memory is load-bearing. It doesn't eliminate it.
The three-question audit
Can a new operator answer three questions from the system itself: what is running, how it is changed, and what assumptions it requires?
The first two yield to the techniques above. The third is harder. It's where self-describing systems reach their limit and traditional documentation earns its place.
If any of those answers require memory, chat logs, or archaeology, the system carries an unmonitored dependency on a specific person's knowledge. That dependency will fail through forgetting, departure, or scale.
Design until forgetting is no longer a failure mode.