Why novelty, scale, and time compression fail together
One factor is mundane. Two are manageable. Three is where failure becomes systemic, because each removes the safety margin the other two need.
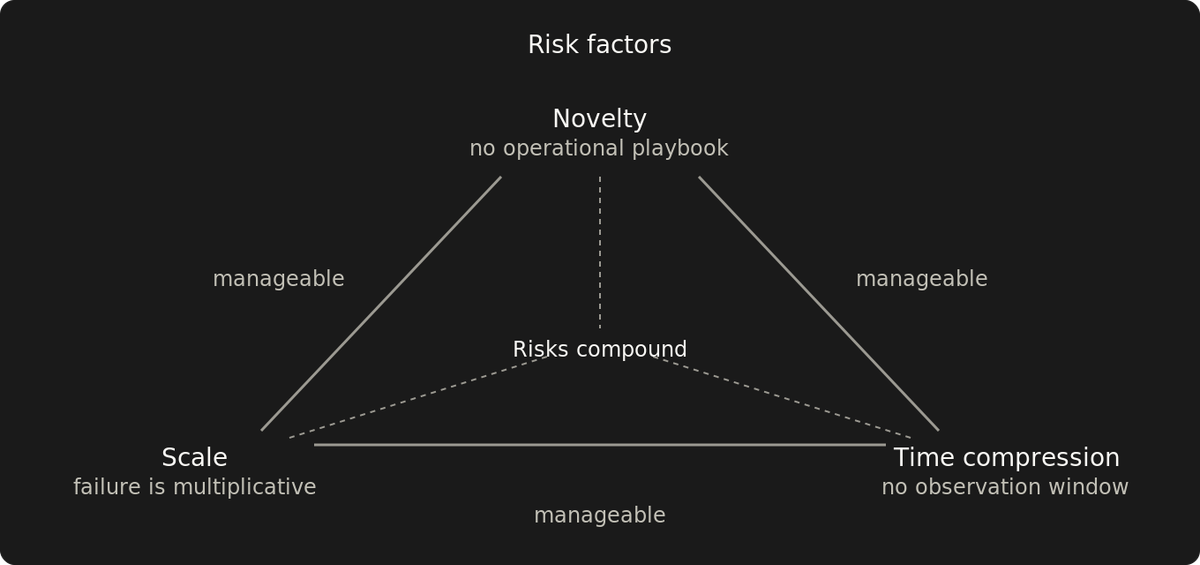
With novelty, scale, and time compression, each removes the safety margin that the other two need.
New technology under deadlines gets adopted, large-scale rollouts with proven tools happen regularly, and novel architectures with enough runway get built. Each pair has precedent. All three, taken together, are approved as separate risks, but fail as a coupled system.
How three manageable risks become one systemic failure
Novelty means no operational playbook exists for this team, in this context. Production history from other organizations doesn't transfer automatically. The failure modes that matter surface under production load or not at all. Some novelty is procedural and shrinks with effort. Structural novelty doesn't — that's the kind that compounds with scale and time compression.
Scale makes failure correlated, because the same artifact runs everywhere. A defect in one deployment is a defect in all of them, and the blast radius is hard to bound because the correlation is hard to predict in advance. Scale is relative to the organization. 100% of customers is large scale, whether that's fifty or fifty million.
Time compression removes observation time. Unknown unknowns need exposure to real conditions to become visible. Compressed timelines kill that window.
All three factors compete for the same resource: observation time. Novelty needs it to build playbooks. Scale needs it to surface correlated failures incrementally. Time compression is what takes it away. When all three are present, the observation budget is already spent before the project starts producing the understanding it needs.
What the failure looks like from inside the project
The failure emerges late. A component that handled ten instances fine starts dropping connections at a thousand. A thundering herd that never appeared in testing forms the first time, every instance retries at once. Debugging requires operational understanding of the system's behavior at scale. That understanding only comes from running the system at scale, which the project hasn't had time to do.
By then, the investment is committed. Recovery narrows to two options: absorb the failure, or start over with less time than the original deadline allowed. You fix one interaction, and it changes a timing or load characteristic that was masking a second failure. That's the signature of coupled failure. The causes are interacting, and isolating any single one doesn't stabilize the system.
Two-factor projects can recover because the remaining safety margin absorbs surprises. Time lets you build the playbook novelty denied. Proven technology lets you recognize failures rather than discover them. Reduced scale lets you contain failure while you learn. The margin is uncomfortable, but it exists. When a three-factor project hits a problem, that margin is already gone.
The three-factor filter
Reject the proposal as structured and reduce it to two.
The filter is a rejection tool. The value is in what it kills early. Pick which two to keep.
The filter catches proposals that look reasonable in review because reviewers evaluate each factor in isolation. "We've handled aggressive timelines before." "We've deployed at this scale before." "We've adopted new technology before." All true. The combination is the risk.
Reducing to two means the mitigated factor no longer removes the safety margin that the other two need. The factor doesn't have to vanish from the proposal. It has to stop interacting destructively with the other two.
Eliminating one factor
Drop novelty
Choose proven technology, but "proven" means proven for this specific use case by this team or a comparable one, not just familiar by name. A platform with an extensive production history elsewhere is still novel if nobody in the organization has operated it under these constraints.
Drop scale
Start small. Reduce the deployment surface — fewer customers, fewer regions, fewer deployments at risk. A novel approach at 10% of traffic is still novel, but a failure contained to that surface is survivable. You learn from it instead of absorbing it everywhere. Two caveats keep that honest. Reducing scale bounds the blast radius. It does not create a rollback path — that needs the change to be reversible, which the surviving novelty can deny. And a failure that rides a shared dependency, like a retry storm against a backend every slice hits, still reaches 100% from a 10% start.
Each scale increment surfaces failures that the previous one didn't, because behavior at one threshold doesn't fully predict the next. Phased this way, the approach reaches full deployment with a playbook at every intermediate scale — as long as each increment runs long enough to surface its failures. That dwell time is observation time, so dropping scale by phasing only works if time compression isn't the factor you kept.
Some systems can't be partially deployed. An authentication provider cutover, or a wire-protocol change with no negotiation path, affects 100% of the system or 0%. For those, dropping scale means deferring until one of the other two factors can be eliminated.
Drop time compression
Push back on the deadline. Observation is what makes novelty at scale survivable, and time compression removes the window in which it can be sustained.
When the deadline can't be moved, buy back time inside it. Split the project into deliverables that ship independently. Independent releases create an observation window between them. That window is what time compression took away.
Make observation a first-class milestone, not something squeezed into whatever time development doesn't have.
Procurement as hidden time compression
Proven technology becomes time-compressed when procurement, licensing, or vendor onboarding consumes the calendar. A platform that needs months of contract negotiation before engineering can start has already spent that time from the deadline.
Already-deployed or pre-authorized tools bypass procurement-induced time compression. But bypassing procurement doesn't automatically satisfy the novelty filter. A deployed tool used in a new context is still novel by the standard defined above.
This is how a two-factor proposal becomes a three-factor proposal. The technology is proven. The scale is known. The timeline looked fine. Then procurement consumes the front end of the schedule, and the remaining calendar no longer has room for the observation the project needs. If the technology isn't deployable when engineering needs to start, it's time-compressed regardless of its track record elsewhere.
Visible cost beats emergent failure
Every factor you drop has a visible cost. A constrained toolset has known tradeoffs. A phased rollout has milestones. A revised deadline has a new date.
Three-factor failure has none of these. The specific failure modes are emergent. Which combination of interacting factors produces which specific failure is unknowable in advance. A failed platform migration takes months to stabilize, and the end date moves until the system is either stable or abandoned.
Dropping a factor feels like admitting the plan was wrong. In practice, it gives the organization a cost it can plan around.
What three-factor failure costs
The costs are real but misattributed. Stabilization gets classified as operational work. The roadmap delay gets attributed to unexpected complexity. The failures compound across all three factors, and each one looks like a reasonable explanation on its own. The three-factor decision doesn't appear in any retrospective.
The same structure gets approved next year.