You can't roll back to a system you already changed
Mutation collapses rollback when you need it most. Coexistence keeps rollback available at every step by running old and new side by side.
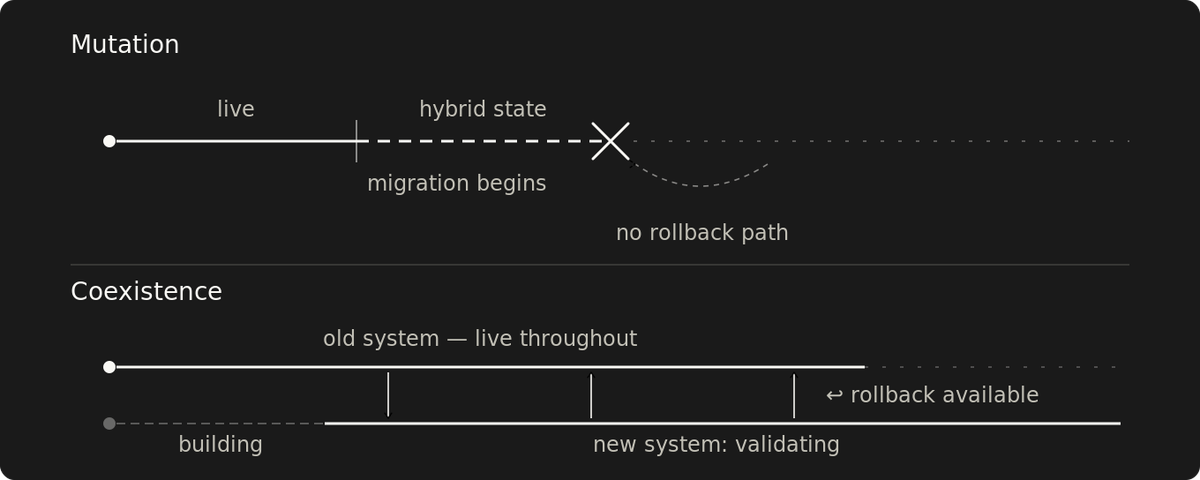
Rollback is a structural property, not a runbook.
The plan is simple: if the new system fails, cut traffic back to the old one. But that plan depends on the old system being recoverable. Mutation changes it in place. If it fails halfway, you're left with a hybrid: part migrated, part not, and the fast rollback path is already gone. Rebuilding the old state from configuration or backups takes longer and carries its own failure modes. That's the failure scenario: a system stuck between states, with no fast path back.
The old system stays recoverable under coexistence. Build the new one alongside it, shift traffic over, and validate against the old system's baseline. The rollback path degrades as components clear, but it remains available until decommissioning.
The new system runs under real load and is measured against that baseline. It will diverge within agreed tolerance, and that's expected: differences that don't affect correctness, or improvements the migration was designed to produce.
Tolerance is declared before the first traffic shift, tied to correctness or SLO impact, and not renegotiated mid-cutover. If the new system drifts past tolerance, traffic switches back. Decommission the old system once the new one has handled enough traffic patterns within tolerance that fixing forward on the rest is acceptable.
Component health hides system-level failure
Validation against the baseline doesn't mean firing up the new system, running a smoke test, and declaring it ready.
The old system has been running in production long enough to show its response times, error rates, latency distributions, and behavior under load spikes. That's the baseline.
Any non-atomic migration creates a hybrid state. The question is whether each step preserves a rollback path. Move one component at a time, and each step keeps a proven return path. Mutation degrades that path with each step. The further you get, the less of the old system exists to return to.
There are two windows, because there are two questions. The first: Does each piece work on its own? Fail a component over to the new version, measure it against the SLO, and fail it back if it misses. But the test spends the very thing it's protecting. Every failover-and-failback round trip costs error budget, and the budget is finite. So you can't probe every component as hard as you'd like. A component that burns too much leaves less to test the rest, and that's what sets the order you test them in.
Once a component has cleared, stop its previous workload while keeping the infrastructure intact. The rollback path degrades from that point.
The second question is different: does the whole thing behave once it's all running together? Now the full system carries production traffic while the old infrastructure stays available for rollback. What you're watching for is the system acting differently under traffic it hasn't met yet: the off-peak lull, the batch run, the sudden spike. You're done when the system has processed enough types of traffic.
If the new system doesn't clear the bar at either window, roll back.
Mutation works when the blast radius is proven
When rollback is cheap (the old state can be rebuilt from configuration, or the change is trivially reversible), coexistence is overhead worth skipping.
Mutation is a bet on prediction. It works when the failure modes are enumerable before the migration starts, and the recovery path is a procedure the team has already executed. The bet gets worse as the migration grows in scope, duration, or the number of components that change state simultaneously.
Mutation cost is invisible
A failed mutation's cost spans incident response, SLA credits, a delayed roadmap, customer churn, and engineering capacity diverted from planned work. None of it shows on the infrastructure invoice. Those costs compound, but the line items don't trace back to the migration decision. Incident response shows up as "operational load." The roadmap slip gets attributed to scope, the SLA credit to "reliability incident."
The coexistence cost is challenged in every budget review because it's a line item with a number attached. The costs of a failed mutation have already been reclassified by the time any budget review happens.
The budget request is for rollback coverage. The old system stays up until the new one proves itself. The duration is an estimate. The exit criteria are operational.
Singleton failover carries a disconnection window
Some components only allow one active instance at a time. The old instance has to stop accepting new work before the new one takes over. Two instances accepting work at once, even briefly, violate the constraint the singleton is meant to enforce. The failover window produces a disconnection. Whether that registers as an outage depends on how the application handles it and whether the duration fits inside the SLO budget.
A stable interface between the component and its consumers enables the cutover. The old instance stops, the new one starts, and consumers don't know which instance is live, because they talk to the interface, not the instance. The interface adds a component that can fail and needs monitoring. That operational cost is the price of hiding the cutover from consumers.
Rollback uses the same interface and the same disconnection window. For stateless components, that makes it symmetric. For stateful components, every write to the new instance since cutover is data that the old instance never saw. The forward operation doesn't carry that burden, but rollback does.
So the cost of rolling back climbs with every write the new instance takes. Track that divergence, keeping the new writes recoverable so a rollback can carry them home, and the cost stays capped. That cap holds only if those writes can replay into the old system, and when they can't, rollback becomes the slow reconciliation that coexistence was meant to avoid. Leave it untracked, and the cost runs away: the longer the new instance runs, the more is thrown away going back. Both the failover and the failback must still finish within the SLO budget. When they can't, the migration has surfaced a resilience gap you have to close.
When the surrounding system can tolerate the brief failover window, the disruption remains confined to where it occurs. The rest of the system talks to the interface, not the component, so the failover doesn't ripple past its consumers. The component fails back on its own, and the blast radius never leaves the compartment.
Calendar time is a bad proxy for decommissioning
Decommissioning the old system tests the discipline. The new system looks good, the old one consumes resources, and pressure to decommission grows daily. Infrastructure bills are visible. Operational burden is real. It feels done.
Every traffic pattern the new system handles reduces the risk of decommissioning. A full weekly cycle covers day-of-week variation. Month-end processing exercises the batch paths. Load spikes fill in the rest on their own schedule. Each checked-off pattern shrinks the set of unknowns that could force a rollback.
Some patterns can't be enumerated in advance: annual regulatory loads, partner integration batches, and failure modes that only appear during regional outages. The observation window catches some. The rest are a judgment call: how much residual risk justifies the ongoing infrastructure cost. No migration reaches zero unknowns. The enumerable patterns get mechanical exit criteria. The residual risk is set to a pre-agreed threshold.
Criteria agreed before the first traffic shift hold when pressure mounts. The SLO is the bar for enumerable patterns. Without that agreement, the decommissioning decision drifts from pattern coverage to "has anyone complained lately," and the pressure starts the moment the new system handles a clean week.
Coexistence costs more and takes longer. That's the price of a rollback path that works when you need it. Every shortcut that removes the old system early is a bet that nothing left will go wrong.
The challenge is not making that bet until the evidence justifies it.