Validation separates self-healing from a keep-alive script
Keep-alive automation checks whether the script ran. Self-healing checks whether the system recovered.
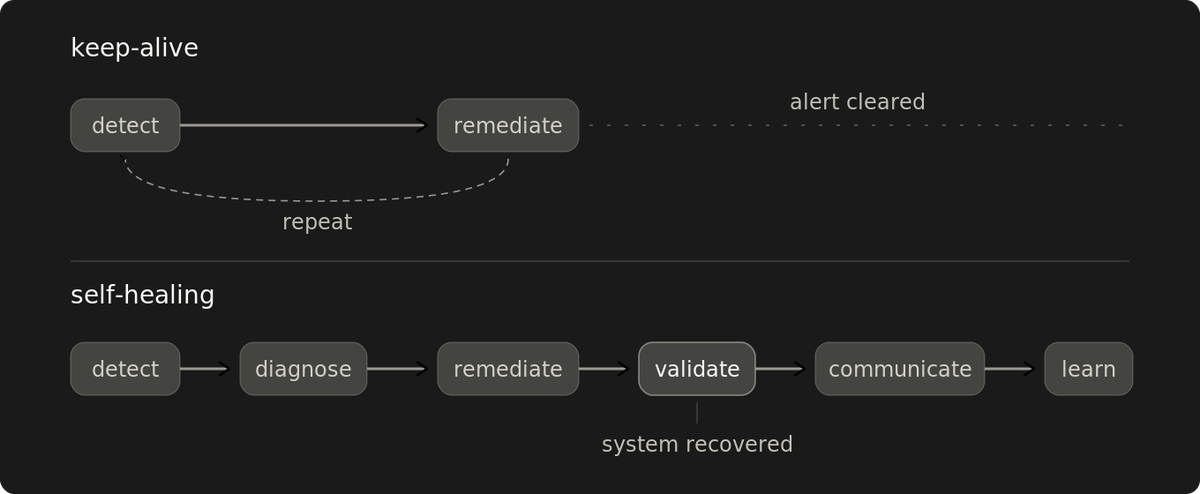
Detection plus restart is a keep-alive script.
The restart fires, the alert closes, and the database connection limit that caused the errors is still exhausted across the fleet. Whether the system recovered is a separate question, and most self-healing automation stops before answering it.
Unsupervised operation depends on the second confirmation. The cheapest place to start is one service, one remediation, one validation gate after the fix. The full pattern grows around that gate in six layers. The validation gate answers one question: what evidence would make this automation refuse to declare success? The other five layers feed and protect that gate.
Where the build usually stops
Most automation ships detection and remediation. Validation is the next layer up, and the one that decides whether the loop can run without a human. Diagnosis feeds its inputs. Communicate and learn keep its gates honest over time.
Detect. Something is wrong. Elevated error rates, resource exhaustion, latency degradation, and failed health checks.
Diagnose. Classify the failure mode: just enough to pick the right remediation. A restart applied to the wrong mode (saturated pool, memory leak, upstream degradation) mutates the state and takes the root-cause evidence with it. A hard restart with no load-balancer drain also drops active connections mid-transaction. A graceful drain keeps the connections but still loses in-memory session state. Diagnosis captures state (heap, pool contents, in-flight connections) before the mutation lands. Capture has a cost, so the set is keyed to the failure mode.
Remediate. The action matches the diagnosis. Restart, scale, failover, rotate stale connections, invalidate cache entries, and rotate credentials. Complex remediation runs as a sequence of stages.
Validate. Confirm the system recovered against the gate's criteria. Completion measures the script. Recovery measures the system. Three outcomes: recovered, not recovered (escalate with diagnostic state preserved), or indeterminate within a time budget (escalate). What counts as recovery depends on the remediation.
The first four layers run per incident. The next two run across incidents.
Communicate. Report what happened, what changed, and who needs to know. Each event has its own audience. A default channel that never reaches the affected audience is just logging, a different operation. A scaling event that lands in the infra team's audit trail but never crosses into the deploying team's channel has been logged, not communicated. The next team ships against stale assumptions about state the automation already changed.
Learn. Track patterns across remediation events. Surface repeat remediation against the same cause, so a human decides whether to fix it or accept the cost. When this layer fails, it fails quietly. Auto-resolved incidents filter out of default queue views while the same remediation fires for weeks. Thresholds tuned to the current noise floor hide the regressions this layer exists to catch.
Validation is where the loop earns autonomy.
Success leaves no trace
Validate, communicate, and learn produce absence by default: the escalation that didn't fire, the team that knew before they had to ask, the permanent fix that arrived before the problem recurred. A working loop looks exactly like a system where nothing broke. Without a gate that explicitly records the counterfactual, there's no log line and no postmortem.
Detection, diagnosis, and remediation create visible incident damage when they fail. Validate, communicate, and learn can fail with the incident still looking resolved. A service swaps its caching layer; the readiness check still probes the old one and keeps passing. A team reorgs, the channel-to-audience map doesn't, and remediation events keep routing to an inbox nobody owns anymore. Review cadences that depend on a fire to trigger them stop catching patterns that never fire. The learn layer drifts because the signal never arrives.
The entry point is small: one service, one remediation, one gate after the fix. The first time the gate returns "not recovered" on a remediation that previously declared success, the counterfactual turns concrete: a specific avoided outage, escalated to the on-call the same way a real failure would be. Each gate earns its place the first time it catches a failure the old automation would have called success.
For a team with a handful of services and low remediation event rates, one gate plus on-call handles it. The rest of the pattern earns its place as event volume grows past what humans can track by hand.
A gate that refuses needs three parts
"Confirm recovery" is the goal. The design has three components.
Readiness criteria per failure mode. Restart, failover, and binary cutover are three distinct validation shapes.
The restart checks that the process is accepting real traffic (not just that it's alive), that dependency handshakes have completed, and that error rate stays below the recovery threshold after a warmup window inside the validation budget. A criterion that requires pre-incident throughput rejects valid recoveries. Throughput after a cold start ramps as caches warm and pools refill.
A graceful failover checks capacity on the target under actual transferred load, downstream dependency response, and post-cutover error rate. For binary cutovers (VIP migration, consensus promotion), there's no incremental load to probe against, so validation reads what the target does on the first committed shift. A DNS flip is different: resolution shifts gradually across the TTL window, so the read is whether the new target accepts traffic while convergence completes. These are checks both liveness and readiness probes miss: a readiness probe confirms one instance can serve, not that the target holds the transferred load.
At small fleet sizes, the criteria live per service. At platform scale, the platform owns shared readiness contracts against declared failure modes, so each service doesn't have to redefine them.
Asymmetric thresholds between trigger and clear. Trigger and clear take different thresholds. For a health-checked service, the down-declaration fires after N consecutive bad samples. The recovered-declaration waits for M consecutive good ones on the same signal, where M is larger than N. The asymmetry is deliberate.
Without it, noisy signals produce flapping: the system switches back the moment the signal crosses, then flips again when the underlying issue twitches. An asymmetric split converts a noisy signal into a stable state decision.
The right shape is workload-specific. Consecutive-sample counts are one option; time-windowed averages and rate-based thresholds are others. Probe cadence, signal-to-noise ratio, and the cost of a wrong switch decide which fits. At high probe cadence, consecutive-sample counts collapse the recovery window to milliseconds, and the shape has to shift to a time-windowed decision.
The asymmetry has a cost. The system stays on the backup path longer than necessary, which matters when the backup is weaker than the primary. And the threshold only decides whether to switch. It says nothing about the switch itself taking time: routing has to converge (DNS TTL, anycast, or service-mesh, depending on the path), the source drains any in-flight connections, and the destination re-establishes sessions. Crossing the threshold is one discrete moment. Reaching it and completing the cutover are not.
Stage gates between remediation steps. Complex remediation runs as a sequence of stages, each followed by a check that the invariant still holds. A failed gate stops forward motion, but "stopping" only helps if the system can hold the current stage indefinitely.
Gates bound forward commitment. Rollback is a separate staged remediation with its own gates. For a progressive deployment with 40% of instances on the new version, "revert" is a second directed operation that has to be designed and tested on its own. Some remediations (schema changes, removed cluster members) have no rollback at all, only compensating forward actions.
For the sequence to be safe on re-run, individual steps still need to be idempotent. Gates alone don't make a leaky operation retry-safe.
Validation is the threshold
Where validation lives depends on the remediation. For restart loops behind external SLO monitoring, the external signal is the validation layer. For remediation that mutates state the system can't cheaply re-observe, validation is a gate inside the automation. The architecture moves. The question doesn't. What would make this automation refuse to declare success?
The gate confirms recovery, preserves the evidence, and keeps the loop moving. Communicate and learn close the gap between what the gate checks and what the system has become. Coordination gaps pull humans back in, no matter how clean the validation is. Gate criteria drift as the system changes around them. When they stop matching, the loop is confirming script completion again: the keep-alive where it started.
Build the gate that can refuse. Without it, everything else is a keep-alive with better tooling.